

Storage Types :
This tab is focused on defining how incoming source data is stored and accumulated within Controller View®. It outlines four types of data storage methods, each with its specific use case:
- Permanent: This method stores data in a single, un-partitioned database table. It’s typically used for reference data or static data that doesn’t change frequently.

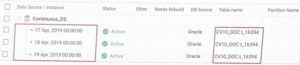
- Continuous: Here, each instance of data is stored in a single table and is marked with a date/time stamp (
ASOFDATE) and instance key (if applicable). This method is suitable for market data or trade data that keeps updating regularly.
-
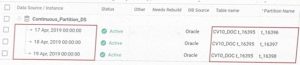
Continuous Partition: Similar to Continuous, but the data is partitioned by date, which helps improve performance and ensures long-term data retention. This method is preferred for large datasets like transactions, positions, and general ledger (GL) data.
-
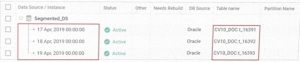
Segmented: Each instance of data is stored in a separate table, making it ideal for cases where you need to store a full daily snapshot of data, such as positions data or frequently changing reference data.
Note:
The Continuous Partition method is generally preferred over the Continuous method because it provides better performance and longevity by organizing data into partitions.
Layout Tab :
The Layout Tab in Controller View® is designed to define the structure of the incoming data source. It provides flexibility in how data is processed by specifying details like column names, column descriptions, data types, and other relevant attributes.
Key Features of the Layout Tab:
-
Data Source Structure Definition: This tab helps define how the incoming data will be structured and processed, specifying attributes for each column such as name, description, and data type.
-
Customizable Fields: You are not required to load all the columns from the incoming data source. Controller View® allows you to skip or hide unwanted fields, giving you flexibility in how you manage the data.
-
Mandatory Basic Layout: You must define a basic layout with at least one column containing mandatory attributes before you can save the new source. This ensures that the data structure is minimally configured.
Layout Setup Methods:
-
Automatically: You can use the ‘Import table layout’ option to import an existing layout from another table that shares a similar structure. This option is useful for quickly replicating an existing configuration.
-
Manually: Alternatively, you can manually list each field (column) required in the Data Source layout grid. You can add new rows by clicking the ‘Add Row’ or ‘Insert Row’ buttons, then define the necessary attributes for each field.
This flexibility in defining the layout ensures that the system can process the data in a way that meets your specific requirements, while also allowing customization based on the structure of the incoming source.
Leave a Reply